Optical Character Recognition (OCR) converts text in scanned images into searchable, readable text. When you scan a document and save it as a PDF, most scanners only capture an image of the text—not actual text that computers and screen readers can interpret. This makes scanned documents inaccessible to people using assistive technology, like screen reading tools.
The quality of the OCR depends on the quality of the scanned image. For example, if a page from a book is scanned and has bends and creases, the OCR may not accurately recognize the text on the page. It is important to use good quality scans when possible.
How to Perform Optical Character Recognition (OCR) in Adobe Acrobat
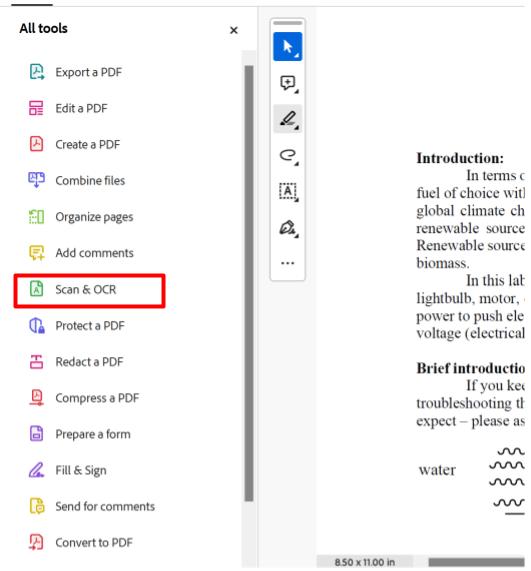
1. Open Adobe Acrobat and select Scan & OCR from the tools menu on the left. If you do not see it, select the More Tools option to add it to your tools menu. Sometimes if you open a scanned document in Adobe Acrobat, you may be prompted to perform the OCR on the document if Adobe detects that the text isn't readable by a computer.
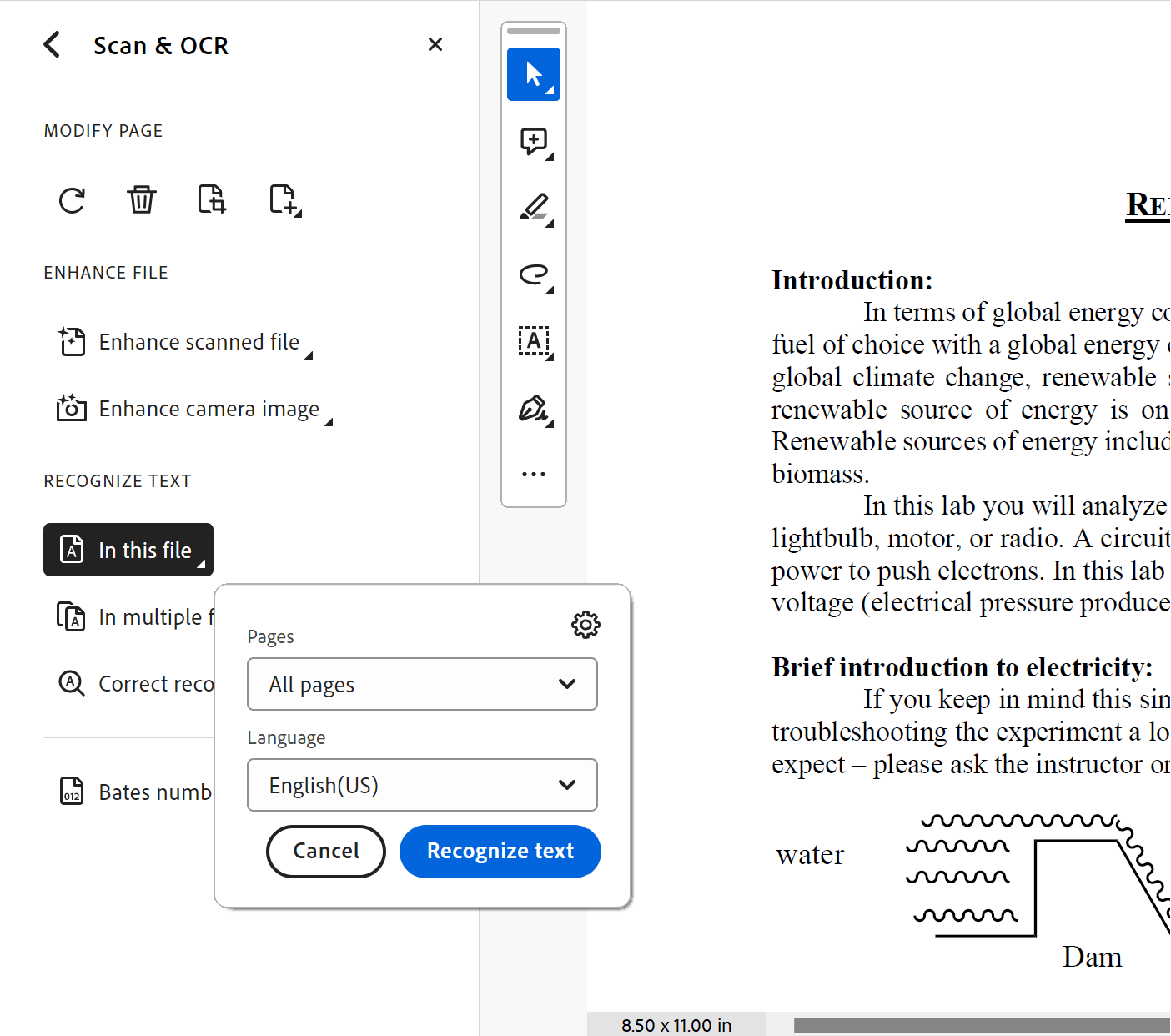
2. Select In This File under the Recognize Text heading.
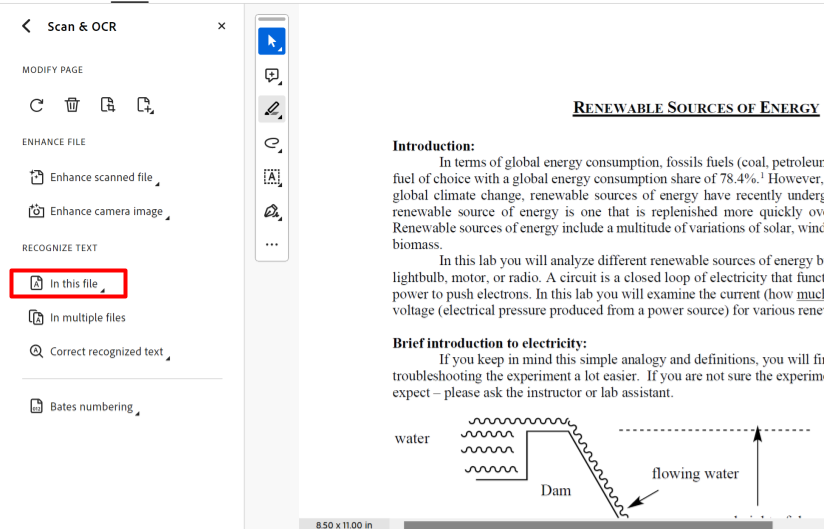
3. Click the blue Recognize Text option. Adobe Acrobat will then run the OCR on the document. Your document should now be readable, selectable, and searchable by a computer and screen reader.